

OpenHermes 2.5 Mistral-7B vs GPT4 for News Writing
Comparing a top Open Source 7B LLM with state-of-the--art GPT4 API from OpenAI

Comparing LLMs (large language models) is hard. For third party black box APIs, we take a look at some examples, and pretty much take their word for it. While open source models live and die by the HuggingFace benchmarks.
The benchmarks themselves, are a sum of many different tests, and I doubt even those running the tests truly understand which of those are significant, recent, relevant, etc.
That said we still tend to get broad consensus on what are the best generative language models at particular model sizes. “Hermes 2.5 Mistral 7B” from Nous Research has emerged as a top 7 billion parameter model for conversational interfaces.

The 7B size is a nice benchmark for models big enough to do “real work” on a variety of practical problems, while small enough to run easily on an AWS GPU or even on your own box. Within a year, it will likely be possibly to run 7B LLMs on your iPhone.
On the “black box API” side, GPT4 remains the gold standard. GPT3.5 is rumored to be a 20B parameter model, while GPT4 is “much bigger” — and 50x as expensive for API calls.
According to Ethan Molnick’s blog and others — GPT4 is “far ahead” of other models on complex tasks like consulting work. But what about a mid-complexity tasks like text summarization?
In particular, we look at Hermes 2.5 vs GPT4 on “news generation.”
Given a set of tweets, clustered based on their LLM embeddings, which contain related, redundant and sometimes contradictory information — write a coherent short news story and a readable headline.
We compare 81 such stories, and judge both stories and headlines, generated independently by Hermes and GPT4.
TL;DR: GPT4 is better at news writing, but in most cases not a lot better.
There are cases where Hermes 2.5 writes better headlines than GPT4, and it’s not entirely just random. More on that below…
But in most cases, the stories are the same — shockingly similar actually. Not just of similar quality, but actually not that easy to tell apart. In a lot of other cases, the GPT4 is slightly better. And in a notable minority of cases GPT4 is much better.
The biggest problem we had with Hermes 2.5 was actually that it sometimes did not generate a well-formatted answer at all. We regenerated or excluded those examples. Possibly user error, but we do think that GPT4 is more reliable at following prompted instructions. (We request the body and headline in JSON form.) Happy to share prompts and technical details on any of that…
In any case, here is what the comparison look like:
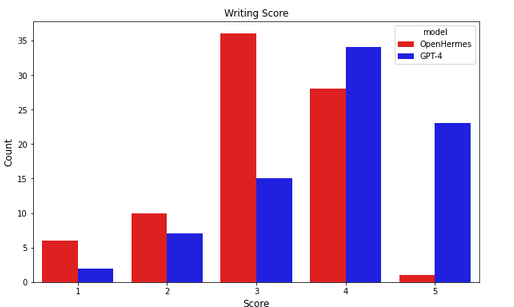

We scored 81 stories on a score of 1-5, both for the story and separately for the headline.
5 = great, ideal
4 = very good
3 = decent, solid
2 = bad
1 = very bad nor irrelevant
If we add up the scores, GPT4 stories (blue graph) are concentrated around total scores of 7-9 — good/great both on story and headline. A few stories get 10/10 and many get 9/10 by our metric.
Hermes 2.5 stories mostly score 7-8, with some 9s and only one 10/10. There are also substantially more scores of 5 and below.

What is surprising though is that we actually get *more* great (4/5) headlines from Hermes than from GPT4. The sample is small, and this is mostly a matter of GPT4 writing imperfect headlines — adding extra words and irrelevant facts and comments. Not really a matter of Hermes being amazing at headline writing. But it does do well.
Looking at a 3x3 confusion matrix of headline buckets, it’s not obvious which model is better.

You can view the dataset and labels here.

Ping us if you would like a better format and we’ll update something better for online browsing.
Overall, I suggest that while GPT4 writes better, and screws up stories less often than Hermes 2.5 — you often can’t even tell which is which, and we are talking about GPT4 compared with a 7B param open source model.
Not to mention that we optimized the writing prompts for GPT4. We use GPT4 on our website. We very much want it to work as good as possible.
Let’s take a look at some examples…
Here is a canonical example where GPT4 writes a better story. The Hermes versions is informative, but GPT4 offers useful additional details.

This one is more of a mixed bag. I’d argue that both stories are ok. GPT-4 writes a better headline, although the Hermes story body is arguably more coherent.

As you also see above, GPT4 has a tendency to shovel in extra facts, sometimes at the expense of coherence and good writing.
Hermes, as a less “powerful” model, seems to skip minor details more readily, for better or for worse.

It also sometimes fudges details — like confusing LeBron’s 37 points for his age — which is actually 38... almost 39.

When clustering bits of information, it’s not always easy to write a coherent story or a crisp headline. At times GPT-4 stuffs too much unrelated info into the story, including into the headline. Even though our prompts discourage long headlines and superfluous information.
In this case, Hermes writes a cleaner headline, although the GPT4 story body is somewhat better.

Clustering is a fast but imperfect way to group related text for stories. Here is an example where clustering groups a few crypto-hack stories together. Hermes 2.5 seems to do a better job summarizing the main hack, avoiding secondary stories. GPT4 tries to mention them all.
You can see the source tweets, in the dataset linked above.

Other cases are more like this... It would easy to distinguish by the style, which story is GPT4 and which is Hermes. GPT4 includes just a bit more details. But I would not say it’s clear which side is better. Both get the job done. Either is fine for the reader, or as input into our RAG chatbot.

From these examples, and more in the doc that we are sharing, I can’t help but conclude that Hermes 2.5 is actually “good enough” at writing news stories, compared with GPT4, at least in most cases — and occasionally it is actually better.
Neither model was finetuned for this task — and all the prompt engineering was optimized for GPT4.
Hence it makes you wonder if for a task like this — cluster, summarize and format the text — the customer using GPT4 finds himself somewhat over-served, to use the parlance of Disruption Theory.
GPT4 is a powerful general purpose model. On the LeBron story, the Obama advisor story, and many other stories, it shows its skill at crafting a great summary over some redundant and confusing or even unrelated facts. But in other cases it’s not needed. Furthermore we have had a very hard time getting GPT4 to:
write short, factual and well structured stories
generate a concise but informative headline
neither over-stuff facts, nor leave the reader hanging [the headline should stand up well alone]
write the story in a coherent style, like Bloomberg for news, or a good sports writer for sports
avoid clickbait style, cliches, and run-on sentences
Hence we are both over-served by GPT4 — it’s bigger and more powerful than we need, with all of the speed and expense that entails — and underserved… it’s really hard to tune GPT4 to do exactly what you want. Especially via instruction, and especially for style.
Ultimately, using a smaller, more malleable model might let us do things we can’t easily do with GPT4
finetune generation on our best responses, or even those with human touch-up
finetune for writing style, especially for sports, crypto or other niches
generate multiple responses and automatically choose the best one (in the time and at lower cost than one GPT4 query)
It’s also likely that open source models will get better. And we only tried the 7B model in any case.
In practice we use GPT3.5 for much of our story writing. The “top” stories all go to GPT4, but writing all of our 2,000+ daily self-updating stories with GPT4 proved too slow given API rate limits. Maybe this is faster now.
As this study would suggest, GPT3.5 does not write stories *all that much worse” than GPT4. Although we see occasional complete hallucinations — and our models detecting bad stories occasionally let one of these through.
We wonder if OpenAI will be putting in much effort to tune, retrain and improve GPT3.5. Possibly not. Even though I think still their most used model API…
I’ve also heard that the GPT3.5 hallucinations could be related to quantization of these models by OpenAI. We tried the quantized version of Hermes 2.5 for this study. It was definitely worse… although not notably worse if we ran it five times and took the best output 😉
This is running long. So I’ll stop here.
Do let us know if you’d like more details on how we write news stories, more details on the study, or comparisons with other models.
Next time I’ll get into how we cluster tweets to generate news story candidates. And which LLM embedding you can use for such a task. We looked at quite a few. I think you’re going to enjoy that one.
Thank you for reading and let me know in the comments below.